OpenClaw 记忆对比:向量化 VS Markdown,到底该怎么选?

OpenClaw 记忆对比:向量化 VS Markdown,到底该怎么选?
青萍叙事前言
你有没有遇到过这种情况:跟 Agent 聊了好几天,它突然像失忆了一样,完全不记得之前说过的配置和偏好。
或者反过来,Agent 确实记住了所有东西,但每次回复都要读一遍几十 KB 的记忆文件,上下文空间被占得满满当当。
记忆管理是 OpenClaw Agent 最容易被忽视、却最关键的能力。它决定了 Agent 能否真正理解你的需求,而不是每次都从零开始。
当前有两种主流方案:向量化记忆和 Markdown 记忆。很多用户在这两者之间纠结。
本文会帮你理清两种方案的核心差异,并结合 Karpathy 的 LLM Wiki 方法论,给出明确的推荐建议。
向量化记忆方案
核心原理
向量化记忆的本质是把文本转换成数学向量。使用嵌入模型(Embedding Model)将每段记忆转为高维空间中的点,然后通过计算向量之间的相似度,找到与当前问题最相关的记忆。

优势
语义检索是向量化方案的最大亮点。它不依赖关键词匹配,而是理解你的意图。比如你问「上次说的那个配置」,它能找到相关记忆,即使你完全没有提到「配置」这个词。
自动压缩功能可以智能总结历史对话,节省上下文空间。跨会话搜索打破了会话边界,让 Agent 真正拥有长期记忆。
可扩展性强,适合海量记忆场景,即使有上千条记忆,检索速度也不会明显下降。
劣势
精度损失是主要问题。压缩过程不可避免地会丢失细节,某些细微的上下文可能无法恢复。
黑盒检索意味着你不可控。你无法精确知道哪些记忆会被召回,有时候重要的记忆没被召回,不相关的反而出现了。
依赖外部 API,需要嵌入模型服务,每次写入和检索都会产生 Token 消耗。如果 API 服务不稳定,记忆功能会直接受影响。
适用场景
长期运行的 Agent 需要跨会话记忆。如果你希望 Agent 记住你几周前的偏好和配置,向量化方案是必选项。
记忆量超过 200 条时优势明显。当记忆数量达到这个规模,手动管理已经变得困难,自动化检索的价值开始体现。
需要语义搜索的场景。当你不记得具体关键词,只能用模糊描述查询时,向量化方案能显著提高召回率。
上下文频繁超限时可以考虑。自动压缩功能可以释放上下文空间,让 Agent 有更多空间处理当前任务。
Markdown 记忆方案
核心原理
Markdown 记忆方案使用结构化文本文件存储记忆。记忆内容以人类可读的格式保存在 .md 文件中,通过目录结构进行分类管理。
管理方式可以是手动或半自动。用户直接编辑文件,或者通过 Agent 工具进行增删改查。代表实现包括 PARA 第二大脑、MEMORY.md 等。
Karpathy LLM Wiki 方法论
最近,前特斯拉 AI 总监、OpenAI 创始成员 Andrej Karpathy 分享了他的 LLM 交互管理方法,核心思想是用简单的文本文件管理所有 LLM 对话和记忆。
核心理念
对话即文档。每次与 LLM 的交互都是一次知识创造,应该像代码一样被记录、版本化、可追溯。
透明可控。你精确知道存储了什么,每条记忆的位置、格式、分类都由你决定。这种透明性对于技术文档、配置信息等重要内容非常关键。
简单优先。不需要复杂的向量数据库、嵌入 API,只需要文本文件和基本的目录结构。越简单的系统越可靠,越容易维护。
实践方法
会话文件化。每次重要对话保存为独立的 .md 文件,包含完整的对话历史和关键结论。文件名包含日期和主题,便于后续查找。
索引文件。维护一个 MEMORY.md 或 INDEX.md 作为记忆索引,记录核心规范、常用配置、关键决策。这个文件是 Agent 每次启动时必读的。
注释驱动。在对话记录中添加注释,标记重要信息、待办事项、关键决策。注释用特殊标记(如 ## 💡 关键决策)突出显示。
版本管理。用 Git 追踪所有记忆文件的变更历史。可以回滚到任意时间点,查看某条信息是什么时候、为什么被记录的。
分类存储。按照 PARA 方法(Projects、Areas、Resources、Archive)或自定义分类组织记忆文件。分类不宜过细,5-10 个类别足够。
为什么有效
Karpathy 方法的核心优势在于人机协同。人类擅长结构化思考和长期规划,LLM 擅长快速生成和处理信息。Markdown 方案让两者各司其职:
- 人类负责分类、归档、清理等战略性工作
- LLM 负责读取、写入、整理等执行性工作
- 双方共享同一套透明的记忆系统,没有黑盒
这种方法在个人知识管理、技术文档、配置管理等场景下表现优异。

优势
完全可控是最大优势。你精确知道存储了什么内容,每条记忆的位置、格式、分类都由你决定。
零成本。不产生额外 API 调用,所有操作都是本地文件读写。
可版本管理。用 Git 追踪变更历史,可以回滚到任意时间点。
易于调试。直接打开文件就能查看内容,排查问题时快速定位。
适合精确保存。技术文档、配置、规范类信息能完整保留。
劣势
文件容易膨胀。没有自动压缩机制,长期积累后单个文件可能达到几十 KB,读取时消耗大量上下文空间。
占用上下文配额。每次读取记忆文件都会消耗 Token,如果文件较大,会挤压当前任务的可用空间。
依赖 LLM 辅助。虽然检索和维护可以交给 LLM,但这会增加额外的 Token 消耗和响应时间。
适用场景
短期会话不需要跨会话记忆。如果 Agent 只需要在当前会话中保持上下文,Markdown 方案足够用。
记忆量小于 100 条时足够用。小规模记忆手动管理并不困难,反而更可控。
需要精确保存的内容。配置信息、技术规范、重要约定等需要完整保留的内容,适合用 Markdown 存储。
技术文档、配置、规范类信息。这类内容本身就以文档形式存在,用 Markdown 存储最自然。
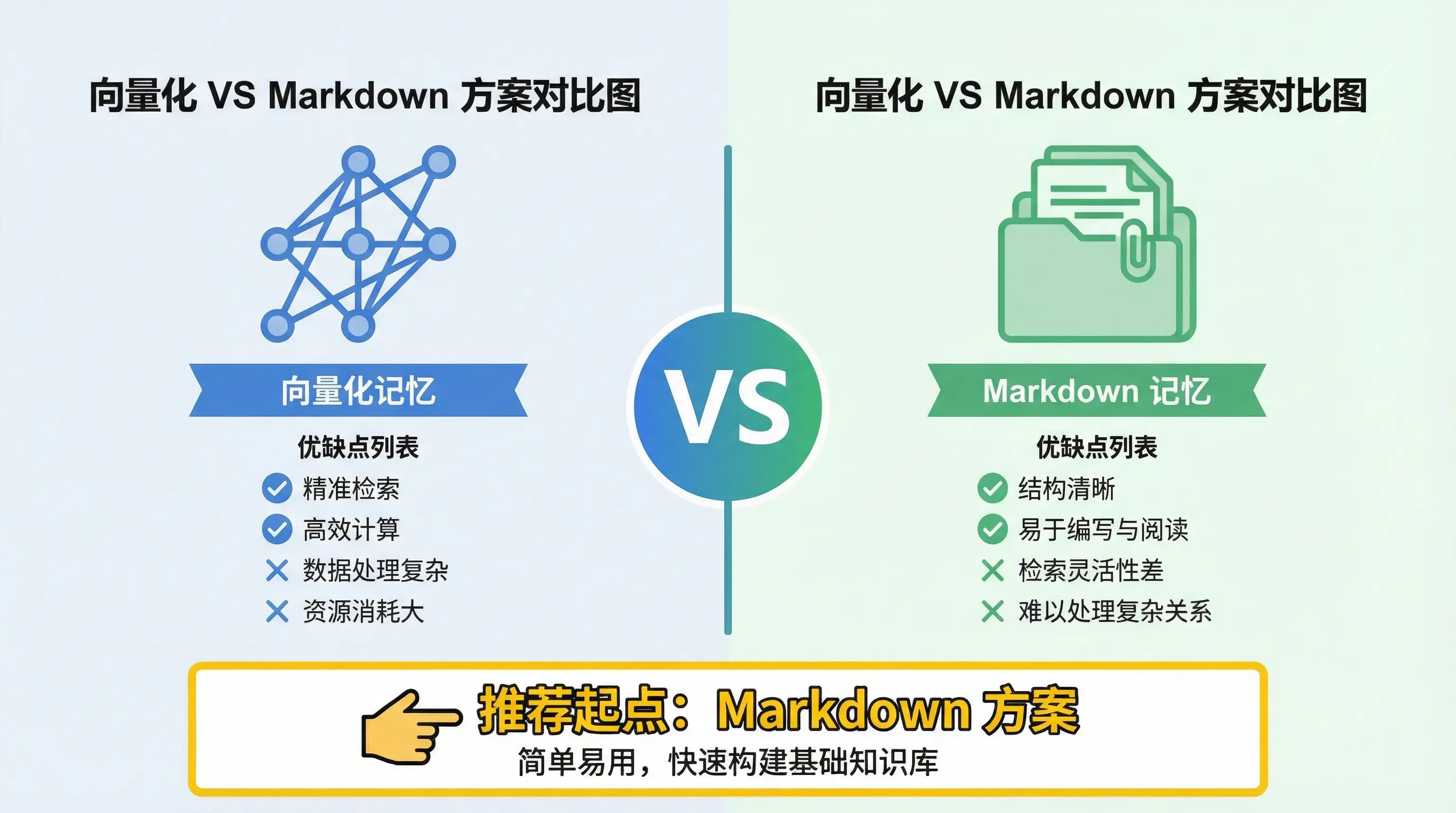
两种方案对比
| 维度 | 向量化 | Markdown |
|---|---|---|
| 检索精度 | 语义匹配,理解意图 | 关键词匹配,精确查找 |
| 成本 | 高(每次 API 调用) | 零(本地文件) |
| 可控性 | 低(黑盒检索) | 高(完全透明) |
| 扩展性 | 强(海量记忆) | 弱(文件膨胀) |
| 维护成本 | 低(自动管理) | 高(手动维护) |
| 适用记忆量 | >200 条 | <100 条 |
| 跨会话支持 | 原生支持 | 需要手动读取 |
| 内容完整性 | 可能损失细节 | 完整保留 |
| 检索速度 | 快(向量索引) | 慢(文件遍历) |
| 隐私性 | 依赖外部 API | 完全本地 |
推荐建议
为什么推荐 Markdown 方案
经过实践验证,Markdown 方案是大多数用户的首选。
Karpathy 方法论的验证
Karpathy 的 LLM Wiki 方法在技术社区获得广泛认可,核心原因是它符合知识工作的本质:
- 透明性比自动化更重要。你知道记忆在哪里,为什么在那里。
- 简单性比功能丰富更重要。简单的系统更可靠,更容易调试。
- 人机协同比全自动更重要。人类负责战略,LLM 负责执行。
实际使用体验
对于个人用户和小团队,Markdown 方案的实际体验更好:
- 设置简单,不需要配置 API、数据库
- 调试方便,直接打开文件就能查看
- 迁移容易,文件可以随意复制、备份
- 隐私安全,所有数据都在本地
向量化方案的优势(语义检索、自动压缩)在记忆量较小时并不明显,但成本和复杂性却是实实在在的。
什么时候考虑向量化
向量化方案并非没有价值。以下场景可以考虑:
- 记忆量超过 200 条,手动管理变得困难
- 企业级多用户记忆管理的复杂场景
- 需要跨大量会话检索,且会话间隔很长
- 预算充足,可以承担持续的 API 费用
- 对语义检索有强需求,经常模糊查询
但即使在这些场景下,也可以考虑混合方案:核心规范用 Markdown,海量对话记忆用向量化。
总结
记忆管理没有银弹,但 Markdown 方案是大多数用户的最佳起点。
向量化和 Markdown 各有优劣,但从实际使用体验、成本、可控性综合考量,Markdown 方案更适合个人用户和小团队。
Karpathy 的 LLM Wiki 方法论为 Markdown 方案提供了理论支撑。
对话即文档、透明可控、简单优先,这些理念正在成为 AI 时代的知识管理共识。
如果你还在犹豫,建议从 Markdown 方案开始。
它设置简单、成本低、可控性强,即使后续需要向量化,也可以平滑迁移。
最后,记住一个原则:记忆是为了更好地服务当前任务,而不是为了存储而存储。无论选择哪种方案,定期清理、保持简洁都是关键。










