AI 配音多音字踩坑记

AI 配音多音字踩坑记
青萍叙事前言
你有没有遇到过这种情况。
花了一下午写好脚本,调好情感参数,满心期待点下生成。
结果 AI 用字正腔圆的播音腔,把你的 重来 读成了 重(zhòng)来。
把 言行一致 读成了 言 háng 一致。
把 了结 读成了 了(le)结。
那一刻的感觉,就像精心做了一桌菜,上桌时发现盐罐子打翻了。
这不是你的错。
多音字,是所有中文 TTS 引擎的噩梦。
今天我把自己踩过的坑一个一个扒出来,咱们看看都是怎么翻车的,最后再说怎么根治。
一个个让人血压升高的翻车现场
先从最常见的说起。
真行 AI 读成了 真 háng。
行 在中文里有 xíng(真行、行走)和 háng(银行、行业)两个读音,TTS 默认给了一脸自信的 háng。
类似的还有一大堆。
重来一次 被读成 重(zhòng)来一次。
在配音脚本里,重来是最常见的高频词之一,偏偏 AI 十次有八次猜错。
了结 被读成 了(le)结。
了 作助词读 le,作动词(了结、了如指掌)读 liǎo。
如果你的角色台词里有一句 这件事必须了结,AI 大概率会把它变成一句没有痛感的陈述。
音乐 和 快乐 也有问题。
对 AI 来说,乐 在音乐里读 yuè,在快乐里读 lè,但有些模型在长句里会串。
走着瞧 被读成 走 zhe 瞧。
着 的四个读音(zhe、zháo、zhāo、zhuó)各有各的用法,AI 从上下文判断准确率时好时坏,尤其在口语化台词里。
长相 读成 相(xiāng)貌。
和 相 相关的翻车案例特别多。
相声 读成 相(xiāng)声,相由心生 读成 相(xiāng)由心生。
还有地名。
我开始做有声小说的那段时间,写过一个发生在广州的场景,脚本里出现了 广州朝阳区。
我用的是广州的 朝(cháo)阳,最终 AI 给的是 朝(zhāo)阳。
多音字错误背后的技术原因
多音字读错不是偶然失误,而是 TTS 技术的结构性难题。
中文里多音字有 1000 多个,其中高频使用的也有几百个。
每个字在不同语境下的读音不同,AI 需要根据上下文猜出正确读音。
问题就出在这个猜上。
现在的 TTS 模型大多基于 Transformer 架构,通过训练数据学习发音规律。
训练数据里,银行 出现的次数远高于某些古文中的 行,所以模型对行的默认倾向是 háng。
同理,重量 远多于 重来,快乐 远多于 音乐(在口语语料中的比例)。
这不是模型能力不够,而是统计分布的惯性。
你写了一个表达精确的句子,AI 用概率最高的读音去念。
巧合的是,概率最高的那个经常不对。
还有一个更隐蔽的问题:长距离依赖。
句子里的多音字,需要结合句子后面甚至几段之前的内容来判断。
如果句子的主语出现在句首,动词在句末,中间隔了三层定语从句,模型就很容易丢失上下文。
创作者常用的四种多音字土办法
多音字翻车实在太普遍了,创作者们早就开始自救。
我总结了几种常见的土办法。
|同音字替换法。
把 了结 改成 了解(但这个意思不对啊),或者把 重来 改成 从头再来。
重虽然还是会读错,但人家换了个写法。
缺点是很多多音字根本找不到合适的同音替代词,强行替换会改变原意。
|拼音标注法。
在文稿里给多音字加拼音,比如 重(chóng)来。
听起来很聪明,对吧?
问题是你得手工给每个字加括号注音,写一千字的稿子,可能有二三十个多音字要处理。
而且加了拼音后原文被破坏,文字排版乱成一团。
|分段生成法。
把长句拆成短句,逐段生成再拼接。
因为短句的上文变少,错误率确实低一些。
缺点是合成出来的语气不连贯,两段之间有明显的断气感。
|避字法。
写稿时故意避开多音字。
这个最省事,但也最离谱。
为了 AI 不读错,创作者连中文词汇都不能自由使用了。
这些方法我全都试过。
不是不能用,但各有各的代价。
你要么牺牲效率,要么牺牲效果,要么同时牺牲这两者。
青萍AI语音如何解决多音字翻车
后来我用青萍 AI 语音做播客时,发现它在语音合成界面上直接提供了一行标注:多音字设置。
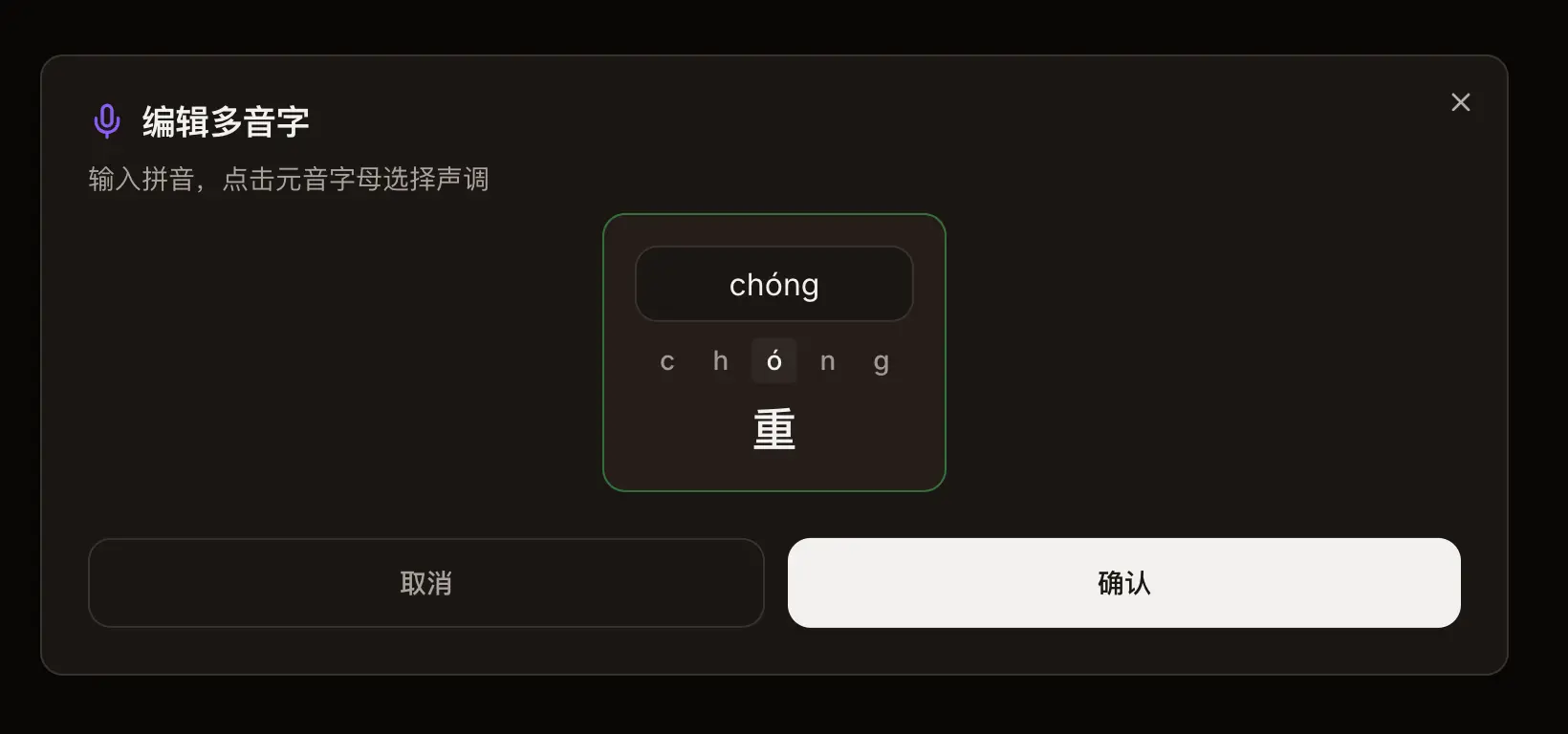
选中文字后,系统会弹出多音字设置面板,展示该字的所有可选读音。
你不需要改原文,不需要加拼音,甚至不需要会注音。
选中 行 字,面板上会出现 xíng 和 háng 两个可选读音。
点一下 xíng 再点确认,AI 就会用正确读音来合成。
对于脚本创作者来说,这个交互方式太关键了。
你审视一遍稿子,遇到多音字点一下就行。
不用改原文结构,不影响排版,不改语法,不改语序,只是告诉 AI 这里读这个音。
我最近做了一个短剧的配音脚本,2000 多字的文案,逐段检查了一遍多音字。
言行一致?选中 行,设为 xíng。
了结这件事?选中 了,设为 liǎo。
有朝一日?选中 朝,设为 zhāo。
走着瞧?选中 着,设为 zháo。
前后花了两分钟过一遍,每处点一下确认就开始生成。
生成的语音里没有出现一个读错的字。
这个功能的妙处在于,不用人工校一遍音后,发现错了再回去改,再重头生成。
你在生成前就排除了所有隐患,一次合成,一步到位。
多音字不该成为内容创作的绊脚石
写稿、调参、合成、校对、重来。
内容创作者的时间本来就紧。
多音字问题说大不大,说小不小。
它不影响 AI 配音的整体质量,但它会让你的听众在关键台词前突然愣住。
一句 重来 读成重来,听众就出戏了。
一个 10 分钟的视频如果有 3 处读错,整个作品的专业感就被拉下来了。
土办法能对付,但不是一个可持续的方案。
青萍 AI 语音的多音字设置功能把这个小问题彻底消灭了。
不需要学 SSML 语法,不需要改原文,不需要分段生成。
写好的稿子点几下鼠标,所有多音字各就各位,然后一次生成。















